过拟合是什么意思模型(过拟合的原因及解决办法)
过拟合是指机器学习模型在训练数据上表现很好,但在新的、未见过的数据上表现较差的现象。这种现象通常是由于模型过于复杂,以至于它“记住”了训练数据中的噪声和细节,而忽略了数据的真实分布。
过拟合的原因及解决办法
过拟合的原因主要有以下几点:
1.模型过于复杂:当模型的复杂度超过数据本身的复杂性时,就会出现过拟合现象。
2.训练数据量不足:如果训练数据量不足以覆盖所有可能的特征,那么模型可能会过度拟合训练数据。
3.训练数据存在噪声:如果训练数据中存在大量的随机误差,那么模型可能会过度拟合这些噪声。
解决过拟合的方法主要有以下几种:
1.增加训练数据量:通过增加训练数据量,可以帮助模型学习到更多的特征,从而减少过拟合的可能性。
2.简化模型:通过减少模型的复杂度,可以降低模型对训练数据的依赖程度,从而减少过拟合的可能性。
3.使用正则化:正则化是一种常用的防止过拟合的技术,它通过在损失函数中加入一个正则项来限制模型的复杂度。
4.使用交叉验证:交叉验证是一种评估模型性能的方法,它可以帮助我们更准确地估计模型在未知数据上的表现,从而避免过拟合。
如何避免过拟合
避免过拟合的方法主要包括以下几点:
1.选择合适的模型:选择适合问题类型的模型,避免使用过于复杂的模型。
2.使用足够的训练数据:确保训练数据量足够大,能够覆盖所有可能的特征。
3.使用数据增强技术:通过对训练数据进行变换、旋转等操作,可以生成更多的训练样本,提高模型的泛化能力。
4.使用早停法:在训练过程中,当验证集的性能不再提升时,停止训练,以防止模型过拟合。
5.使用dropout技术:在训练过程中,随机丢弃一部分神经元,可以有效防止过拟合。
总结
过拟合是机器学习中的一个常见问题,它会导致模型在新数据上表现不佳。为了避免过拟合,我们需要选择合适的模型、使用足够的训练数据、使用数据增强技术、使用早停法和dropout技术等方法。
相关阅读
-

解决幼猫晚上一直叫的问题需要我们从多个方面入手,包括了解幼猫的情况、观察幼猫的行为、提供适当的照顾等。希望以上内容能帮助您更好地照顾幼猫,让它健康成长。...
2024-04-24 7054 -

总之,面对猫咪在新家里遇到的困难,我们需要耐心、细心地去解决。只有这样,我们才能帮助猫咪顺利地适应新家,过上幸福的生活。...
2024-04-24 2242 -

新来的小猫可能会因为不熟悉环境而感到不安和害怕,这是很正常的。但是,只要你给予足够的关注和陪伴,以及使用适当的猫咪安抚产品和方法,你的小猫一定能够很快地适应新环境,不再那么害......
2024-04-24 1007 -

总之,E2错误是海尔燃气热水器常见的故障之一。通过了解E2错误的含义、可能原因以及解决方法,我们可以更好地应对这个问题。同时,我们还可以通过预防E2错误的方法,延长热水器的使......
2024-04-23 9354 -

美的洗衣机E21作为一款性能优越的洗衣机,在使用过程中可能会遇到一些故障。本文对美的洗衣机E21的常见故障进行了详细的解析,并提供了相应的解决方法。希望这些方法能够帮助您解决......
2024-04-23 8981 -

总之,影响因子为10.0的论文具有较高的学术价值和影响力,涵盖了各个学科领域。虽然发表这样的论文面临一定的挑战,但对于希望发表高质量研究论文的人来说,仍然是一个难得的机遇。通......
2024-03-25 5193 -
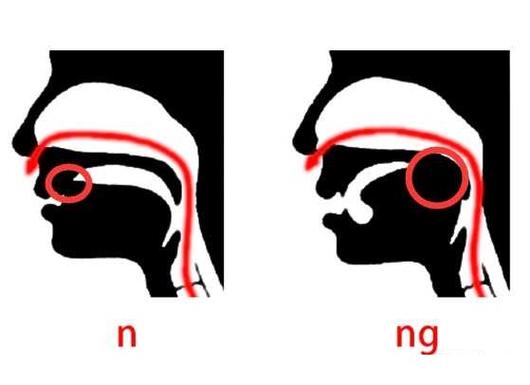
以下就是关于如何区分前鼻音和后鼻音的拼音技巧,以及含有轻声音节的拼音读法的一些基本知识。希望这些信息能够帮助大家更好地学习和掌握汉语拼音。在学习的过程中,如果遇到任何问题,都......
2024-03-24 4108 -

总之,在职研究生可以考博,但难度较大,需要具备较强的学术能力和研究能力。在职研究生的含金量相对较低,但在职业发展方面具有一定的优势。因此,在职研究生在选择考博时,应充分考虑自......
2024-03-24 2295 -

红外线水平仪是一种非常实用的工具,可以帮助用户在不接触物体的情况下,准确地测量物体的水平和垂直角度。通过掌握正确的使用方法和选择合适的基准,可以大大提高测量的准确性和效率。在......
2024-03-23 9464 -

班本课程是幼儿园教育的重要组成部分,它以幼儿为中心,关注幼儿的全面发展,有助于提高教育质量,培养具有创新精神和实践能力的幼儿。因此,我们应该重视班本课程的实施,充分发挥其价值......
2024-03-23 2830 -

总之,矩阵中的e通常表示自然对数的底数,即欧拉数。在矩阵运算中,e与指数函数、对数函数、三角函数和阶乘函数都有着密切的关系。这些关系使得矩阵中的e在许多实际应用中具有重要价值......
2024-03-22 8341
发表评论

